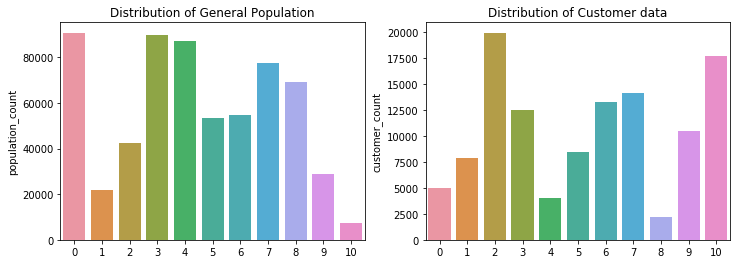Identify segments of the population that form the core customer base for a mail-order sales company in Germany. These segments can then be used to direct marketing campaigns towards audiences that will have the highest expected rate of returns.
Project: Identify Customer Segments
In this project, you will apply unsupervised learning techniques to identify segments of the population that form the core customer base for a mail-order sales company in Germany. These segments can then be used to direct marketing campaigns towards audiences that will have the highest expected rate of returns. The data that you will use has been provided by our partners at Bertelsmann Arvato Analytics, and represents a real-life data science task.
This notebook will help you complete this task by providing a framework within which you will perform your analysis steps. In each step of the project, you will see some text describing the subtask that you will perform, followed by one or more code cells for you to complete your work. Feel free to add additional code and markdown cells as you go along so that you can explore everything in precise chunks. The code cells provided in the base template will outline only the major tasks, and will usually not be enough to cover all of the minor tasks that comprise it.
It should be noted that while there will be precise guidelines on how you should handle certain tasks in the project, there will also be places where an exact specification is not provided. There will be times in the project where you will need to make and justify your own decisions on how to treat the data. These are places where there may not be only one way to handle the data. In real-life tasks, there may be many valid ways to approach an analysis task. One of the most important things you can do is clearly document your approach so that other scientists can understand the decisions you’ve made.
At the end of most sections, there will be a Markdown cell labeled Discussion. In these cells, you will report your findings for the completed section, as well as document the decisions that you made in your approach to each subtask. Your project will be evaluated not just on the code used to complete the tasks outlined, but also your communication about your observations and conclusions at each stage.
1 2 3 4 5 6 7 8 9 10 11
# import libraries here; add more as necessary import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import re from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA from sklearn.cluster import KMeans # magic word for producing visualizations in notebook %matplotlib inline
Step 0: Load the Data
There are four files associated with this project (not including this one):
Udacity_AZDIAS_Subset.csv: Demographics data for the general population of Germany; 891211 persons (rows) x 85 features (columns).
Udacity_CUSTOMERS_Subset.csv: Demographics data for customers of a mail-order company; 191652 persons (rows) x 85 features (columns).
Data_Dictionary.md: Detailed information file about the features in the provided datasets.
AZDIAS_Feature_Summary.csv: Summary of feature attributes for demographics data; 85 features (rows) x 4 columns
Each row of the demographics files represents a single person, but also includes information outside of individuals, including information about their household, building, and neighborhood. You will use this information to cluster the general population into groups with similar demographic properties. Then, you will see how the people in the customers dataset fit into those created clusters. The hope here is that certain clusters are over-represented in the customers data, as compared to the general population; those over-represented clusters will be assumed to be part of the core userbase. This information can then be used for further applications, such as targeting for a marketing campaign.
To start off with, load in the demographics data for the general population into a pandas DataFrame, and do the same for the feature attributes summary. Note for all of the .csv data files in this project: they’re semicolon (;) delimited, so you’ll need an additional argument in your read_csv() call to read in the data properly. Also, considering the size of the main dataset, it may take some time for it to load completely.
Once the dataset is loaded, it’s recommended that you take a little bit of time just browsing the general structure of the dataset and feature summary file. You’ll be getting deep into the innards of the cleaning in the first major step of the project, so gaining some general familiarity can help you get your bearings.
1 2 3 4 5
# Load in the general demographics data. azdias = pd.read_csv('Udacity_AZDIAS_Subset.csv',sep=';')
# Load in the feature summary file. feat_info = pd.read_csv('AZDIAS_Feature_Summary.csv',sep=';')
1 2 3 4 5 6
# Check the structure of the data after it's loaded (e.g. print the number of # rows and columns, print the first few rows). # Info for general demographics data. print("Total number of rows: {}".format(azdias.shape[0])) print("Total number of columns: {}".format(azdias.shape[1])) azdias.head()
Total number of rows: 891221
Total number of columns: 85
AGER_TYP
ALTERSKATEGORIE_GROB
ANREDE_KZ
CJT_GESAMTTYP
FINANZ_MINIMALIST
FINANZ_SPARER
FINANZ_VORSORGER
FINANZ_ANLEGER
FINANZ_UNAUFFAELLIGER
FINANZ_HAUSBAUER
...
PLZ8_ANTG1
PLZ8_ANTG2
PLZ8_ANTG3
PLZ8_ANTG4
PLZ8_BAUMAX
PLZ8_HHZ
PLZ8_GBZ
ARBEIT
ORTSGR_KLS9
RELAT_AB
0
-1
2
1
2.0
3
4
3
5
5
3
...
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
1
-1
1
2
5.0
1
5
2
5
4
5
...
2.0
3.0
2.0
1.0
1.0
5.0
4.0
3.0
5.0
4.0
2
-1
3
2
3.0
1
4
1
2
3
5
...
3.0
3.0
1.0
0.0
1.0
4.0
4.0
3.0
5.0
2.0
3
2
4
2
2.0
4
2
5
2
1
2
...
2.0
2.0
2.0
0.0
1.0
3.0
4.0
2.0
3.0
3.0
4
-1
3
1
5.0
4
3
4
1
3
2
...
2.0
4.0
2.0
1.0
2.0
3.0
3.0
4.0
6.0
5.0
5 rows × 85 columns
1 2 3 4
# info for the feature summary file print("Total number of rows: {}".format(feat_info.shape[0])) print("Total number of columns: {}".format(feat_info.shape[1])) feat_info.head()
Total number of rows: 85
Total number of columns: 4
attribute
information_level
type
missing_or_unknown
0
AGER_TYP
person
categorical
[-1,0]
1
ALTERSKATEGORIE_GROB
person
ordinal
[-1,0,9]
2
ANREDE_KZ
person
categorical
[-1,0]
3
CJT_GESAMTTYP
person
categorical
[0]
4
FINANZ_MINIMALIST
person
ordinal
[-1]
Tip: Add additional cells to keep everything in reasonably-sized chunks! Keyboard shortcut esc --> a (press escape to enter command mode, then press the ‘A’ key) adds a new cell before the active cell, and esc --> b adds a new cell after the active cell. If you need to convert an active cell to a markdown cell, use esc --> m and to convert to a code cell, use esc --> y.
Step 1: Preprocessing
Step 1.1: Assess Missing Data
The feature summary file contains a summary of properties for each demographics data column. You will use this file to help you make cleaning decisions during this stage of the project. First of all, you should assess the demographics data in terms of missing data. Pay attention to the following points as you perform your analysis, and take notes on what you observe. Make sure that you fill in the Discussion cell with your findings and decisions at the end of each step that has one!
Step 1.1.1: Convert Missing Value Codes to NaNs
The fourth column of the feature attributes summary (loaded in above as feat_info) documents the codes from the data dictionary that indicate missing or unknown data. While the file encodes this as a list (e.g. [-1,0]), this will get read in as a string object. You’ll need to do a little bit of parsing to make use of it to identify and clean the data. Convert data that matches a ‘missing’ or ‘unknown’ value code into a numpy NaN value. You might want to see how much data takes on a ‘missing’ or ‘unknown’ code, and how much data is naturally missing, as a point of interest.
As one more reminder, you are encouraged to add additional cells to break up your analysis into manageable chunks.
1 2 3
# How much data is naturally missing in the dataset for each column. nature_missing = azdias.isna().sum() nature_missing[nature_missing != 0]
# Identify missing or unknown data values and convert them to NaNs. pattern = re.compile(r'\-\d+|\d+') # find all numbers for i in range (len(feat_info)): index = pattern.findall(feat_info['missing_or_unknown'][i]) index = list(map(int, index)) azdias.iloc[:,i] = azdias.iloc[:,i].replace(index,np.nan)
1 2 3 4 5
pattern = re.compile(r'[A-Z]+') # find all XX i = np.arange(57,60) for each in i: index = pattern.findall(feat_info['missing_or_unknown'][each])[0] azdias.iloc[:,each] = azdias.iloc[:,each].replace(index,np.nan)
1 2 3
# How mcuh data takes on a 'missing' or 'unknown' code indicated_miss = azdias.isna().sum()-nature_missing indicated_miss[indicated_miss != 0]
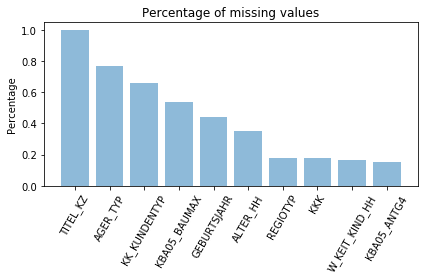
How much missing data is present in each column? There are a few columns that are outliers in terms of the proportion of values that are missing. You will want to use matplotlib’s hist() function to visualize the distribution of missing value counts to find these columns. Identify and document these columns. While some of these columns might have justifications for keeping or re-encoding the data, for this project you should just remove them from the dataframe. (Feel free to make remarks about these outlier columns in the discussion, however!)
For the remaining features, are there any patterns in which columns have, or share, missing data?
1 2 3 4 5 6
# Perform an assessment of how much missing data there is in each column of the dataset.
From the graph above we can see top six variables have over 30% values are missing, those should be removed.
1 2 3 4 5
# Remove the outlier columns from the dataset. (You'll perform other data # engineering tasks such as re-encoding and imputation later.) remove_names = list(count_nan[0:6].index) deleted_var = azdias[remove_names] # save deleted variables azdias.drop(remove_names,axis=1,inplace=True)
1
print("Total number of columns: {}".format(azdias.shape[1]))
Total number of columns: 79
1 2 3 4
# Investigate patterns in the amount of missing data in each column. count_nan = azdias.isna().sum().sort_values(ascending = False) count_nan = count_nan[count_nan != 0] count_nan
Discussion 1.1.2: Assess Missing Data in Each Column
Some columns have exactly the same amount of missing values, which means they might also share those missing values. The variables which have more than 30% missing values are deleted. The deleted variables are TITEL_KZ, AGER_TYP, KK_KUNDENTYP, KBA05_BAUMAX, GEBURTSJAHR, ALTER_HH.
Step 1.1.3: Assess Missing Data in Each Row
Now, you’ll perform a similar assessment for the rows of the dataset. How much data is missing in each row? As with the columns, you should see some groups of points that have a very different numbers of missing values. Divide the data into two subsets: one for data points that are above some threshold for missing values, and a second subset for points below that threshold.
In order to know what to do with the outlier rows, we should see if the distribution of data values on columns that are not missing data (or are missing very little data) are similar or different between the two groups. Select at least five of these columns and compare the distribution of values.
You can use seaborn’s countplot() function to create a bar chart of code frequencies and matplotlib’s subplot() function to put bar charts for the two subplots side by side.
To reduce repeated code, you might want to write a function that can perform this comparison, taking as one of its arguments a column to be compared.
Depending on what you observe in your comparison, this will have implications on how you approach your conclusions later in the analysis. If the distributions of non-missing features look similar between the data with many missing values and the data with few or no missing values, then we could argue that simply dropping those points from the analysis won’t present a major issue. On the other hand, if the data with many missing values looks very different from the data with few or no missing values, then we should make a note on those data as special. We’ll revisit these data later on. Either way, you should continue your analysis for now using just the subset of the data with few or no missing values.
1 2 3 4 5
# How much data is missing in each row of the dataset? row_miss = azdias.isna().sum(axis = 1) sns.countplot(row_miss) plt.xticks(rotation = 90,fontsize=10) plt.show()
1 2 3 4
# Write code to divide the data into two subsets based on the number of missing # values in each row. azdias_no_miss = azdias[azdias.isna().sum(axis = 1) == 0] azdias_with_miss = azdias[azdias.isna().sum(axis = 1) >= 1]
1 2 3 4
# Compare the distribution of values for at least five columns where there are # no missing values, between the two subsets.
list(azdias.isna().sum().sort_values().head(20).index) # choose columns with no missing values
I divide the dataset in two subsets, one without missing values and the other with missing values. I did this because rows without missing values takes the big amount.
The data with missing values is not qualitatively different from the data with no missing values, based on five bar charts above.
Step 1.2: Select and Re-Encode Features
Checking for missing data isn’t the only way in which you can prepare a dataset for analysis. Since the unsupervised learning techniques to be used will only work on data that is encoded numerically, you need to make a few encoding changes or additional assumptions to be able to make progress. In addition, while almost all of the values in the dataset are encoded using numbers, not all of them represent numeric values. Check the third column of the feature summary (feat_info) for a summary of types of measurement.
For numeric and interval data, these features can be kept without changes.
Most of the variables in the dataset are ordinal in nature. While ordinal values may technically be non-linear in spacing, make the simplifying assumption that the ordinal variables can be treated as being interval in nature (that is, kept without any changes).
Special handling may be necessary for the remaining two variable types: categorical, and ‘mixed’.
In the first two parts of this sub-step, you will perform an investigation of the categorical and mixed-type features and make a decision on each of them, whether you will keep, drop, or re-encode each. Then, in the last part, you will create a new data frame with only the selected and engineered columns.
Data wrangling is often the trickiest part of the data analysis process, and there’s a lot of it to be done here. But stick with it: once you’re done with this step, you’ll be ready to get to the machine learning parts of the project!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# How many features are there of each data type? # azdias_less_miss # use dataset with less missing values for each in remove_names: feat_info = feat_info[feat_info['attribute'] != each] categorical_v = feat_info[feat_info['type'] == 'categorical'] ordinal_v = feat_info[feat_info['type'] == 'ordinal'] numeric_v = feat_info[feat_info['type'] == 'numeric'] mixed_v = feat_info[feat_info['type'] == 'mixed'] interval_v = feat_info[feat_info['type'] == 'interval']
print("Total number of numeric variables: {}".format(len(numeric_v))) print("Total number of interval variables: {}".format(len(interval_v))) print("Total number of ordinal variables: {}".format(len(ordinal_v))) print("Total number of categorical variables: {}".format(len(categorical_v))) print("Total number of mixed variables: {}".format(len(mixed_v)))
Total number of numeric variables: 6
Total number of interval variables: 0
Total number of ordinal variables: 49
Total number of categorical variables: 18
Total number of mixed variables: 6
Step 1.2.1: Re-Encode Categorical Features
For categorical data, you would ordinarily need to encode the levels as dummy variables. Depending on the number of categories, perform one of the following:
For binary (two-level) categoricals that take numeric values, you can keep them without needing to do anything.
There is one binary variable that takes on non-numeric values. For this one, you need to re-encode the values as numbers or create a dummy variable.
For multi-level categoricals (three or more values), you can choose to encode the values using multiple dummy variables (e.g. via OneHotEncoder), or (to keep things straightforward) just drop them from the analysis. As always, document your choices in the Discussion section.
1 2 3 4 5 6
# Assess categorical variables: which are binary, which are multi-level, and # which one needs to be re-encoded? binary_v = ['ANREDE_KZ', 'GREEN_AVANTGARDE','SOHO_KZ','VERS_TYP','OST_WEST_KZ'] # all binary variables and 'OST_WEST_KZ' should be re-encoded multi_level_v=categorical_v for each in binary_v: multi_level_v = multi_level_v[multi_level_v['attribute'] != each]
1 2 3 4
# Re-encode categorical variable(s) to be kept in the analysis. # re-encode the binary variable azdias_no_miss.loc[:, 'OST_WEST_KZ'] = azdias_no_miss.loc[:, 'OST_WEST_KZ'].replace('O',0) azdias_no_miss.loc[:, 'OST_WEST_KZ'] = azdias_no_miss.loc[:, 'OST_WEST_KZ'].replace('W',1)
# Change the original dataset names = list(multi_level_v['attribute']) azdias_no_miss.drop(names,axis=1,inplace = True) azdias_no_miss = pd.concat([azdias_no_miss, multi_level_full],axis=1 ) encoded = list(azdias_no_miss.columns) print("{} total features after one-hot encoding.".format(len(encoded)))
191 total features after one-hot encoding.
Discussion 1.2.1: Re-Encode Categorical Features
For binary variable ‘OST_WEST_KZ’ I transform it to numeric values, For multi-level variables I transform all of them into dummy variables.
Step 1.2.2: Engineer Mixed-Type Features
There are a handful of features that are marked as “mixed” in the feature summary that require special treatment in order to be included in the analysis. There are two in particular that deserve attention; the handling of the rest are up to your own choices:
“PRAEGENDE_JUGENDJAHRE” combines information on three dimensions: generation by decade, movement (mainstream vs. avantgarde), and nation (east vs. west). While there aren’t enough levels to disentangle east from west, you should create two new variables to capture the other two dimensions: an interval-type variable for decade, and a binary variable for movement.
“CAMEO_INTL_2015” combines information on two axes: wealth and life stage. Break up the two-digit codes by their ‘tens’-place and ‘ones’-place digits into two new ordinal variables (which, for the purposes of this project, is equivalent to just treating them as their raw numeric values).
If you decide to keep or engineer new features around the other mixed-type features, make sure you note your steps in the Discussion section.
Be sure to check Data_Dictionary.md for the details needed to finish these tasks.
# Investigate "PRAEGENDE_JUGENDJAHRE" and engineer two new variables. # movement: 1 for Mainstream, 0 for Avantgarde movement = azdias_no_miss['PRAEGENDE_JUGENDJAHRE'] == 1 | 3 | 5 | 8 | 10 | 12 | 14 movement = movement.astype(int) decade = [] i = 0 temp = azdias_no_miss['PRAEGENDE_JUGENDJAHRE'] for each in temp: if each == 1or each == 2: i = 1 elif each == 3or each == 4: i = 2 elif each == 5or each == 6or each == 7: i = 3 elif each == 8or each ==9: i = 4 elif each == 10or each ==11or each ==12or each ==13: i = 5 else: i = 6 decade.append(i)
1 2 3 4
# Investigate "CAMEO_INTL_2015" and engineer two new variables. wealth = azdias_no_miss['CAMEO_INTL_2015'].astype(int)/10 wealth = wealth.astype(int) life_stage = azdias_no_miss['CAMEO_INTL_2015'].astype(int) % 10
1 2 3
# Drop original columns and add the new columns names = list(mixed_v['attribute']) azdias_no_miss.drop(names,axis=1,inplace = True)
I transformed “PRAEGENDE_JUGENDJAHRE” and “CAMEO_INTL_2015” . For other variables I just dropped them since some are overlapped with existed variables, for example, “LP_LEBENSPHASE_GROB”.
Step 1.2.3: Complete Feature Selection
In order to finish this step up, you need to make sure that your data frame now only has the columns that you want to keep. To summarize, the dataframe should consist of the following:
All numeric, interval, and ordinal type columns from the original dataset.
Binary categorical features (all numerically-encoded).
Engineered features from other multi-level categorical features and mixed features.
Make sure that for any new columns that you have engineered, that you’ve excluded the original columns from the final dataset. Otherwise, their values will interfere with the analysis later on the project. For example, you should not keep “PRAEGENDE_JUGENDJAHRE”, since its values won’t be useful for the algorithm: only the values derived from it in the engineered features you created should be retained. As a reminder, your data should only be from the subset with few or no missing values.
1 2
# If there are other re-engineering tasks you need to perform, make sure you # take care of them here. (Dealing with missing data will come in step 2.1.)
1 2
# Do whatever you need to in order to ensure that the dataframe only contains # the columns that should be passed to the algorithm functions.
Step 1.3: Create a Cleaning Function
Even though you’ve finished cleaning up the general population demographics data, it’s important to look ahead to the future and realize that you’ll need to perform the same cleaning steps on the customer demographics data. In this substep, complete the function below to execute the main feature selection, encoding, and re-engineering steps you performed above. Then, when it comes to looking at the customer data in Step 3, you can just run this function on that DataFrame to get the trimmed dataset in a single step.
defclean_data(df): """ Perform feature trimming, re-encoding, and engineering for demographics data INPUT: Demographics DataFrame OUTPUT: Trimmed and cleaned demographics DataFrame """ feat_info = pd.read_csv('AZDIAS_Feature_Summary.csv',sep=';') # Put in code here to execute all main cleaning steps: # convert missing value codes into NaNs, ... # Identify missing or unknown data values and convert them to NaNs. pattern = re.compile(r'\-\d+|\d+') # find all numbers for i in range (len(feat_info)): index = pattern.findall(feat_info['missing_or_unknown'][i]) index = list(map(int, index)) df.iloc[:,i] = df.iloc[:,i].replace(index,np.nan) pattern = re.compile(r'[A-Z]+') # find all XX i = np.arange(57,60) for each in i: index = pattern.findall(feat_info['missing_or_unknown'][each])[0] df.iloc[:,each] = df.iloc[:,each].replace(index,np.nan) # remove selected columns and rows, ... count_nan = df.isna().sum().sort_values(ascending = False) count_nan = count_nan[count_nan != 0] # sort the counts remove_names = ['TITEL_KZ','AGER_TYP','KK_KUNDENTYP','KBA05_BAUMAX','GEBURTSJAHR','ALTER_HH']# save deleted variables df.drop(remove_names,axis=1,inplace=True) azdias_no_miss = df[df.isna().sum(axis = 1) == 0] azdias_with_miss = df[df.isna().sum(axis = 1) >= 1] # select, re-encode, and engineer column values. for each in remove_names: feat_info = feat_info[feat_info['attribute'] != each] categorical_v = feat_info[feat_info['type'] == 'categorical'] ordinal_v = feat_info[feat_info['type'] == 'ordinal'] numeric_v = feat_info[feat_info['type'] == 'numeric'] mixed_v = feat_info[feat_info['type'] == 'mixed'] interval_v = feat_info[feat_info['type'] == 'interval'] binary_v = ['ANREDE_KZ', 'GREEN_AVANTGARDE','SOHO_KZ','VERS_TYP','OST_WEST_KZ'] # all binary variables and 'OST_WEST_KZ' should be re-encoded multi_level_v=categorical_v for each in binary_v: multi_level_v = multi_level_v[multi_level_v['attribute'] != each] azdias_no_miss.loc[:, 'OST_WEST_KZ'] = azdias_no_miss.loc[:, 'OST_WEST_KZ'].replace('O',0) azdias_no_miss.loc[:, 'OST_WEST_KZ'] = azdias_no_miss.loc[:, 'OST_WEST_KZ'].replace('W',1) # re-encode the multi-level variables multi_level_row = azdias_no_miss[multi_level_v['attribute']] multi_level_full = pd.get_dummies(multi_level_row.astype(str)) # Change the original dataset names = list(multi_level_v['attribute']) azdias_no_miss.drop(names,axis=1,inplace = True) azdias_no_miss = pd.concat([azdias_no_miss, multi_level_full],axis=1 ) movement = azdias_no_miss['PRAEGENDE_JUGENDJAHRE'] == 1 | 3 | 5 | 8 | 10 | 12 | 14 movement = movement.astype(int) decade = [] i = 0 temp = azdias_no_miss['PRAEGENDE_JUGENDJAHRE'] for each in temp: if each == 1or each == 2: i = 1 elif each == 3or each == 4: i = 2 elif each == 5or each == 6or each == 7: i = 3 elif each == 8or each ==9: i = 4 elif each == 10or each ==11or each ==12or each ==13: i = 5 else: i = 6 decade.append(i) # Investigate "CAMEO_INTL_2015" and engineer two new variables. wealth = azdias_no_miss['CAMEO_INTL_2015'].astype(int)/10 wealth = wealth.astype(int) life_stage = azdias_no_miss['CAMEO_INTL_2015'].astype(int) % 10 # Drop original columns and add the new columns names = list(mixed_v['attribute']) azdias_no_miss.drop(names,axis=1,inplace = True) azdias_no_miss['movement'] = movement azdias_no_miss['decade'] = decade azdias_no_miss['wealth'] = wealth azdias_no_miss['life_stage'] = life_stage
# Return the cleaned dataframe. return azdias_no_miss
Step 2: Feature Transformation
Step 2.1: Apply Feature Scaling
Before we apply dimensionality reduction techniques to the data, we need to perform feature scaling so that the principal component vectors are not influenced by the natural differences in scale for features. Starting from this part of the project, you’ll want to keep an eye on the API reference page for sklearn to help you navigate to all of the classes and functions that you’ll need. In this substep, you’ll need to check the following:
sklearn requires that data not have missing values in order for its estimators to work properly. So, before applying the scaler to your data, make sure that you’ve cleaned the DataFrame of the remaining missing values. This can be as simple as just removing all data points with missing data, or applying an Imputer to replace all missing values. You might also try a more complicated procedure where you temporarily remove missing values in order to compute the scaling parameters before re-introducing those missing values and applying imputation. Think about how much missing data you have and what possible effects each approach might have on your analysis, and justify your decision in the discussion section below.
For the actual scaling function, a StandardScaler instance is suggested, scaling each feature to mean 0 and standard deviation 1.
For these classes, you can make use of the .fit_transform() method to both fit a procedure to the data as well as apply the transformation to the data at the same time. Don’t forget to keep the fit sklearn objects handy, since you’ll be applying them to the customer demographics data towards the end of the project.
1 2
# If you've not yet cleaned the dataset of all NaN values, then investigate and # do that now.
1 2 3 4
# Apply feature scaling to the general population demographics data. scaler = StandardScaler() azdias_trans = pd.DataFrame(scaler.fit_transform(azdias_no_miss)) azdias_trans.columns = azdias_no_miss.columns
Discussion 2.1: Apply Feature Scaling
I removed all missing values brfore, and I transformed all features with StandardScaler.
Step 2.2: Perform Dimensionality Reduction
On your scaled data, you are now ready to apply dimensionality reduction techniques.
Use sklearn’s PCA class to apply principal component analysis on the data, thus finding the vectors of maximal variance in the data. To start, you should not set any parameters (so all components are computed) or set a number of components that is at least half the number of features (so there’s enough features to see the general trend in variability).
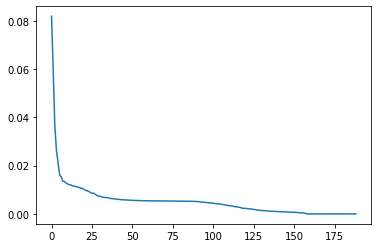
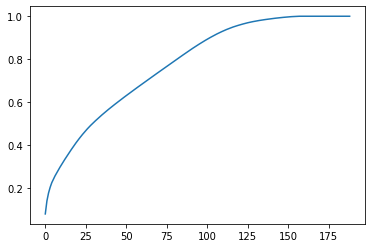
Check out the ratio of variance explained by each principal component as well as the cumulative variance explained. Try plotting the cumulative or sequential values using matplotlib’s plot() function. Based on what you find, select a value for the number of transformed features you’ll retain for the clustering part of the project.
Once you’ve made a choice for the number of components to keep, make sure you re-fit a PCA instance to perform the decided-on transformation.
1 2 3 4
# Apply PCA to the data. from sklearn.decomposition import PCA pca = PCA() azdias_pca = pca.fit_transform(azdias_trans)
1 2 3
# Investigate the variance accounted for by each principal component. var_ratio = pca.explained_variance_ratio_ plt.plot(var_ratio)
[<matplotlib.lines.Line2D at 0x1f0a9327e08>]
1
plt.plot(np.cumsum(var_ratio))
[<matplotlib.lines.Line2D at 0x1f0a8f7dc08>]
1 2 3
# Re-apply PCA to the data while selecting for number of components to retain. pca = PCA(n_components=100) azdias_pca = pca.fit_transform(azdias_trans)
Discussion 2.2: Perform Dimensionality Reduction
With 100 components, over 80% variance can be explained. Thus I choose 100 components.
Step 2.3: Interpret Principal Components
Now that we have our transformed principal components, it’s a nice idea to check out the weight of each variable on the first few components to see if they can be interpreted in some fashion.
As a reminder, each principal component is a unit vector that points in the direction of highest variance (after accounting for the variance captured by earlier principal components). The further a weight is from zero, the more the principal component is in the direction of the corresponding feature. If two features have large weights of the same sign (both positive or both negative), then increases in one tend expect to be associated with increases in the other. To contrast, features with different signs can be expected to show a negative correlation: increases in one variable should result in a decrease in the other.
To investigate the features, you should map each weight to their corresponding feature name, then sort the features according to weight. The most interesting features for each principal component, then, will be those at the beginning and end of the sorted list. Use the data dictionary document to help you understand these most prominent features, their relationships, and what a positive or negative value on the principal component might indicate.
You should investigate and interpret feature associations from the first three principal components in this substep. To help facilitate this, you should write a function that you can call at any time to print the sorted list of feature weights, for the i-th principal component. This might come in handy in the next step of the project, when you interpret the tendencies of the discovered clusters.
1 2 3 4 5 6
# Map weights for the first principal component to corresponding feature names # and then print the linked values, sorted by weight. # HINT: Try defining a function here or in a new cell that you can reuse in the # other cells. feature_select = pd.DataFrame(pca.components_,columns=azdias_trans.columns).T feature_select[0].sort_values()
# Map weights for the third principal component to corresponding feature names # and then print the linked values, sorted by weight. feature_select[2].sort_values()
Component 1: Movement patterns and social status are negatively correlated, which means higher movement higher income. Also wealth and social status are positively correlated. Therefore, the first component is correalted with people’s wealth.
Component 2: Estimated age based on given name analysis is negatively correlated with variable decade, since they are negatively correlated by nature. Thus this one is correlated with ages.
Component 3: People who is not likely to be dreamful is more likely to be a male. This Component is related to the gender.
Step 3: Clustering
Step 3.1: Apply Clustering to General Population
You’ve assessed and cleaned the demographics data, then scaled and transformed them. Now, it’s time to see how the data clusters in the principal components space. In this substep, you will apply k-means clustering to the dataset and use the average within-cluster distances from each point to their assigned cluster’s centroid to decide on a number of clusters to keep.
Use sklearn’s KMeans class to perform k-means clustering on the PCA-transformed data.
Then, compute the average difference from each point to its assigned cluster’s center. Hint: The KMeans object’s .score() method might be useful here, but note that in sklearn, scores tend to be defined so that larger is better. Try applying it to a small, toy dataset, or use an internet search to help your understanding.
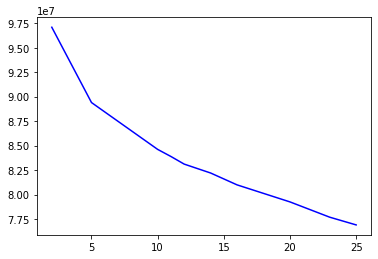
Perform the above two steps for a number of different cluster counts. You can then see how the average distance decreases with an increasing number of clusters. However, each additional cluster provides a smaller net benefit. Use this fact to select a final number of clusters in which to group the data. Warning: because of the large size of the dataset, it can take a long time for the algorithm to resolve. The more clusters to fit, the longer the algorithm will take. You should test for cluster counts through at least 10 clusters to get the full picture, but you shouldn’t need to test for a number of clusters above about 30.
Once you’ve selected a final number of clusters to use, re-fit a KMeans instance to perform the clustering operation. Make sure that you also obtain the cluster assignments for the general demographics data, since you’ll be using them in the final Step 3.3.
1 2 3 4 5 6 7 8
# Function to calculate K-Means score for a centroid
defget_kmeans_score(data, center): kmeans = KMeans(n_clusters = center, random_state=2020) model = kmeans.fit(data) score = np.abs(model.score(data)) return score
# Investigate the change in within-cluster distance across number of clusters. # HINT: Use matplotlib's plot function to visualize this relationship.
plt.plot(centroids,score,color='blue')
[<matplotlib.lines.Line2D at 0x1f0a955a4c8>]
1 2 3 4
# Re-fit the k-means model with the selected number of clusters and obtain # cluster predictions for the general population demographics data. kmeans = KMeans(n_clusters = 11, random_state=2020) result = kmeans.fit_predict(azdias_pca)
Discussion 3.1: Apply Clustering to General Population
The first elbow occurs at ‘n_clusters = 5’, the second elbow occurs at 11, therefore I choose 11 centroids.
Step 3.2: Apply All Steps to the Customer Data
Now that you have clusters and cluster centers for the general population, it’s time to see how the customer data maps on to those clusters. Take care to not confuse this for re-fitting all of the models to the customer data. Instead, you’re going to use the fits from the general population to clean, transform, and cluster the customer data. In the last step of the project, you will interpret how the general population fits apply to the customer data.
Don’t forget when loading in the customers data, that it is semicolon (;) delimited.
Apply the same feature wrangling, selection, and engineering steps to the customer demographics using the clean_data() function you created earlier. (You can assume that the customer demographics data has similar meaning behind missing data patterns as the general demographics data.)
Use the sklearn objects from the general demographics data, and apply their transformations to the customers data. That is, you should not be using a .fit() or .fit_transform() method to re-fit the old objects, nor should you be creating new sklearn objects! Carry the data through the feature scaling, PCA, and clustering steps, obtaining cluster assignments for all of the data in the customer demographics data.
1 2
# Load in the customer demographics data. customers = pd.read_csv('Udacity_CUSTOMERS_Subset.csv',sep=';')
1 2 3 4
# Apply preprocessing, feature transformation, and clustering from the general # demographics onto the customer data, obtaining cluster predictions for the # customer demographics data. customers.shape
# cluster predictions for the customer data. kmeans = KMeans(n_clusters = 11, random_state=2020) result_customer = kmeans.fit_predict(customers_pca)
Step 3.3: Compare Customer Data to Demographics Data
At this point, you have clustered data based on demographics of the general population of Germany, and seen how the customer data for a mail-order sales company maps onto those demographic clusters. In this final substep, you will compare the two cluster distributions to see where the strongest customer base for the company is.
Consider the proportion of persons in each cluster for the general population, and the proportions for the customers. If we think the company’s customer base to be universal, then the cluster assignment proportions should be fairly similar between the two. If there are only particular segments of the population that are interested in the company’s products, then we should see a mismatch from one to the other. If there is a higher proportion of persons in a cluster for the customer data compared to the general population (e.g. 5% of persons are assigned to a cluster for the general population, but 15% of the customer data is closest to that cluster’s centroid) then that suggests the people in that cluster to be a target audience for the company. On the other hand, the proportion of the data in a cluster being larger in the general population than the customer data (e.g. only 2% of customers closest to a population centroid that captures 6% of the data) suggests that group of persons to be outside of the target demographics.
Take a look at the following points in this step:
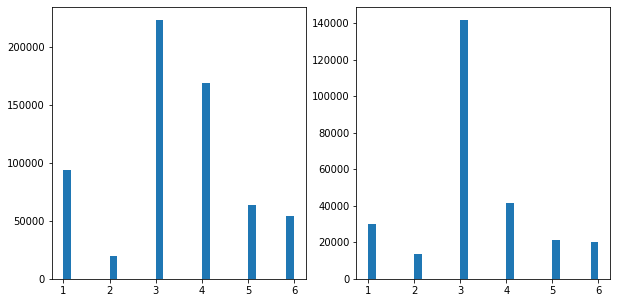
Compute the proportion of data points in each cluster for the general population and the customer data. Visualizations will be useful here: both for the individual dataset proportions, but also to visualize the ratios in cluster representation between groups. Seaborn’s countplot() or barplot() function could be handy.
Recall the analysis you performed in step 1.1.3 of the project, where you separated out certain data points from the dataset if they had more than a specified threshold of missing values. If you found that this group was qualitatively different from the main bulk of the data, you should treat this as an additional data cluster in this analysis. Make sure that you account for the number of data points in this subset, for both the general population and customer datasets, when making your computations!
Which cluster or clusters are overrepresented in the customer dataset compared to the general population? Select at least one such cluster and infer what kind of people might be represented by that cluster. Use the principal component interpretations from step 2.3 or look at additional components to help you make this inference. Alternatively, you can use the .inverse_transform() method of the PCA and StandardScaler objects to transform centroids back to the original data space and interpret the retrieved values directly.
Perform a similar investigation for the underrepresented clusters. Which cluster or clusters are underrepresented in the customer dataset compared to the general population, and what kinds of people are typified by these clusters?
1 2 3 4 5 6 7 8 9
# Compare the proportion of data in each cluster for the customer data to the # proportion of data in each cluster for the general population. result_customer = pd.Series(result_customer) customer_dist = result_customer.value_counts().sort_index() result = pd.Series(result) population_dist = result.value_counts().sort_index() final_df = pd.DataFrame([population_dist,customer_dist]).T final_df.columns = ['population_count','customer_count'] final_df
population_count
customer_count
0
90763
4965
1
22018
7866
2
42219
19958
3
89706
12487
4
87209
3989
5
53588
8490
6
54843
13308
7
77417
14154
8
69022
2203
9
28866
10496
10
7558
17727
1 2 3 4 5 6 7 8
fig = plt.figure(figsize=(12,4)) ax1 = fig.add_subplot(1,2,1) sns.barplot(x=final_df.index,y='population_count', data = final_df) plt.title("Distribution of General Population") ax2 = fig.add_subplot(1,2,2) sns.barplot(x=final_df.index,y='customer_count', data = final_df) plt.title("Distribution of Customer data") plt.show()
# What kinds of people are part of a cluster that is overrepresented in the # customer data compared to the general population? Category 10 cc10 = kmeans.cluster_centers_[10] cc10 = pd.Series(cc10) cc10.sort_values(ascending=False, inplace=True) cc10.head()
# What kinds of people are part of a cluster that is underrepresented in the # customer data compared to the general population? Category 4 cc4 = kmeans.cluster_centers_[4] cc4 = pd.Series(cc4) cc4.sort_values(ascending=False, inplace=True) cc4.head()
Discussion 3.3: Compare Customer Data to Demographics Data
Overrepresented: The category 10, which represents females who are dreamful and might be single parent with child of full age. Underrepresented: The category 4, which represents elderly independent workers with age greater than 60, financial typology is ‘be prepared’.
Congratulations on making it this far in the project! Before you finish, make sure to check through the entire notebook from top to bottom to make sure that your analysis follows a logical flow and all of your findings are documented in Discussion cells. Once you’ve checked over all of your work, you should export the notebook as an HTML document to submit for evaluation. You can do this from the menu, navigating to File -> Download as -> HTML (.html). You will submit both that document and this notebook for your project submission.